


How On-Device AI Works: When Algorithms Run Directly on Hardware
 Tornike Moss
Tornike Moss
For years, artificial intelligence relied on centralized cloud servers as its primary computing environment. However, the rapid expansion of global networks and the growing demand for real-time computation have exposed the physical limits of this model. When billions of devices and sensors continuously transmit data to remote data centers, internet infrastructure increasingly faces critical constraints such as latency, bandwidth saturation, and connection instability. In this context, every millisecond matters, and constant communication with distant servers becomes both inefficient and often unsustainable. In response to these fundamental limitations, the computing paradigm is undergoing a structural shift, moving processing capabilities closer to where data is generated.
At the core of this transformation is On-Device AI — a system-level approach in which pre-trained neural networks are embedded directly into local hardware. Instead of sending raw data to the cloud, the system performs inference directly on the device without relying on external servers. A closer look at how AI is shifting from cloud to devices highlights a new phase in which devices evolve from passive transmitters into independent intelligent nodes. Local computation not only reduces latency but also improves security and energy efficiency, ultimately establishing a new standard for decentralized internet architecture.
Quick Summary
Key takeaways: The main ideas and conclusions of the article are summarized below.
- Centralized cloud-based AI is constrained by latency, bandwidth limitations, and connection instability.
- Massive data streams from IoT devices, sensors, and video systems overload traditional infrastructure.
- On-device AI relies on pre-trained models that perform inference directly on local hardware.
- Local computation reduces network load, improves speed, and enhances energy efficiency.
- Model optimization techniques such as quantization, pruning, and distillation enable efficient edge deployment.
- Edge AI transforms devices into independent intelligent compute nodes.
- Decentralized architectures improve system resilience and eliminate single points of failure.
- On-device intelligence represents a fundamental shift in internet architecture toward distributed computing.
Table of Contents
Limits of Centralized AI Architecture and the Structural Shift
The early development of artificial intelligence was largely dependent on centralized cloud infrastructure, where massive computational resources were concentrated in a small number of global data centers. While this model enabled the training and deployment of large-scale neural networks, the rapid scaling of modern digital ecosystems has exposed its fundamental weaknesses. For systems operating in real time and under critical constraints, the traditional client-server model encounters strict physical and network limitations. Constant data transfer between devices and remote servers is no longer practical or efficient. As a result, the industry has been forced to move computational power closer to the source of data generation, driving a broader transition toward decentralized architectures.
Latency as a Physical Constraint
Data transmission across networks is bounded by physical limits defined by the speed of light and routing processes. In optical fiber, signals propagate at approximately 200,000 kilometers per second, meaning that even intercontinental communication requires tens of milliseconds under ideal conditions. In real-world network environments, where traffic congestion and suboptimal routing are common, latency often rises to 150–300 milliseconds.
When an edge device sends data to the cloud and waits for a response, it introduces round-trip time (RTT), which becomes a critical bottleneck for real-time systems. In autonomous vehicles, where decision windows often range between 10 and 50 milliseconds, or in medical sensors that must react within microseconds, such delays are effectively unacceptable.
Latency, therefore, is no longer just a networking issue — it is a physical constraint that determines where computation must occur: centrally or directly on the device.
Data Streams and Infrastructure Overload
The exponential growth of connected sensors, high-resolution cameras, and IoT devices has created an unprecedented surge in data generation. A single 4K video camera operating at 30 frames per second can produce a continuous stream of 5–15 Mbps. Thousands of such devices within a single city generate network traffic that places significant strain on global infrastructure.
In industrial environments, the scale increases even further. Autonomous vehicles, equipped with multiple cameras, radar, and lidar systems, can generate hundreds of megabits per second. Continuously transferring such volumes of data to the cloud is not only expensive but also architecturally inefficient.
Modern systems therefore shift toward processing raw data locally, transmitting only processed outputs or anomalies across the network. This approach significantly reduces bandwidth usage while improving overall system efficiency.
Dependence on Centralized Systems
Cloud-centric AI architectures make devices critically dependent on network connectivity. When the system’s “brain” resides on a remote continent, any local disruption — whether due to network outages, routing failures, or server overload — can degrade or completely halt system functionality. This type of architectural dependency is unacceptable for systems that require autonomy and high reliability.
Loss of connectivity often results in a sharp reduction of device capabilities. This reliability gap forces engineers to rethink system design. Devices operating in remote locations, drones, and emergency response equipment require guaranteed continuous operation, which is only achievable through local intelligence that does not depend on centralized infrastructure.
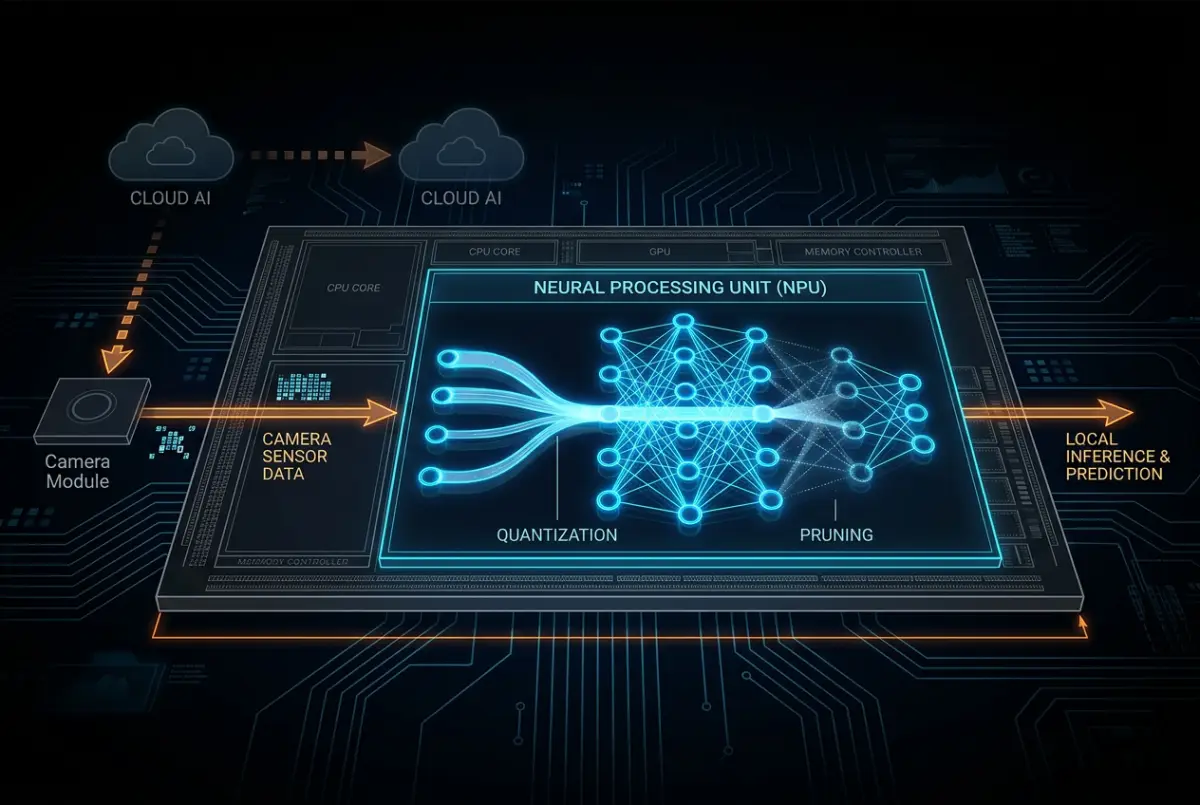
On-Device Intelligence: How AI Operates at the Hardware Level
To address these challenges, the technology industry has developed On-Device Intelligence — a concept that separates the AI lifecycle into two distinct phases: training and inference. While training still requires the immense computational power of cloud infrastructure, completed pre-trained models are deployed directly onto end-user hardware. As a result, devices gain the ability to process incoming signals locally, executing complex algorithms directly on-device without any reliance on network connectivity.
Transferring Pre-Trained Models from Cloud to Device
The development of neural networks begins on large-scale server clusters, where thousands of GPUs process terabytes of data over extended periods. The output of this process is a pre-trained model — a structured matrix of fixed parameters and weights that has learned to recognize patterns within specific domains. To enable AI at the device level, this finalized model is exported and embedded into local hardware such as smartphones, IoT sensors, or cameras as part of its persistent memory.
This approach eliminates the need for devices to learn from scratch. Instead, they inherit a centralized knowledge base and apply it to new, unseen data. By offloading the training phase entirely to the cloud, the system retains only the components required for efficient local computation.
Inference Pipeline on the Device
Once the model is stored locally, the inference phase runs directly on the device’s chip. The process begins with preprocessing the incoming data — including normalization, resizing, and noise reduction — before passing it through the layers of the neural network.
Modern devices rely on specialized hardware accelerators such as Apple Neural Engine, Qualcomm Hexagon DSP, or Google Edge TPU, all optimized for matrix operations. These components enable inference to be executed within 10–50 milliseconds, often consuming only a few watts of power.
As a result, tasks such as facial recognition, voice command processing, and object detection can be performed in real time without any connection to the cloud.
Model Optimization for Resource-Constrained Environments
Models designed for cloud environments are typically too large and computationally intensive for direct deployment on edge devices. To address this, several optimization techniques are applied. Quantization reduces 32-bit floating-point values to 8-bit integer representations, decreasing model size by up to four times while improving execution speed.
Pruning simplifies neural networks by removing redundant connections, often eliminating 70–90% of parameters with minimal impact on accuracy. Knowledge distillation further enhances efficiency by allowing smaller models to replicate the behavior of larger ones while requiring significantly fewer resources.
Through these combined techniques, models containing billions of parameters can be compressed and adapted to run efficiently on smartphones and embedded systems.
Edge AI as the Foundation of Distributed Internet Architecture
The widespread adoption of on-device computation has fundamentally reshaped internet architecture. Instead of a model where peripheral devices act as passive endpoints and all intelligence is concentrated in centralized systems, a decentralized infrastructure is emerging. In this new topology, billions of devices at the edge of the network function as independent intelligent nodes, capable of both collecting and interpreting data in real time. This transformation changes the entire logic of data flow, enabling a more secure, responsive, and scalable global network.
Devices as Independent Compute Nodes
Within the Edge AI paradigm, devices undergo a fundamental transformation in their role. A smart camera or industrial sensor is no longer just a data collector — it becomes a fully functional compute node. When embedded AI models analyze data locally, such as detecting defects on a production line or recognizing a user’s face, the device can make autonomous decisions without cloud authorization.
This shift distributes computational power across the network edge. The dominance of centralized servers diminishes as intelligence moves closer to the physical environments where data originates. Devices evolve into active participants in computation, performing initial data interpretation at the moment of generation.
Local Computation and Reduced Network Dependence
Executing inference locally fundamentally alters how data moves through the system. Instead of continuously transmitting full video or audio streams, devices send only processed results, such as detected objects or identified anomalies.
This approach can reduce network traffic by more than 90% while significantly lowering latency. As a result, applications such as augmented reality, real-time translation, and video analytics become viable on everyday devices.
At the same time, energy consumption decreases and device autonomy improves — a critical factor for mobile and battery-powered systems.
Decentralized Architecture and System Resilience
The resilience and reliability of any information system are defined by its ability to continue operating under failure conditions. A decentralized edge architecture ensures that the failure of a single server or backbone connection does not lead to a system-wide collapse. Since each device functions as an independent intelligent unit, it can continue executing critical tasks even in complete offline conditions.
This architectural resilience is particularly important for medical implants, smart city infrastructure, and defense systems, where even temporary loss of connectivity can have severe consequences. By eliminating single points of failure, decentralization makes systems structurally more resilient and adaptable.
On-Device Intelligence is no longer merely an optimization strategy — it represents a fundamental shift in how internet systems are designed. As computation moves closer to the source of data, systems become faster, more autonomous, and inherently more resilient. This transition defines the future of digital infrastructure, where intelligence is distributed rather than centralized.
Go backComments (0)
From This Author
Select Crypto to Support the Author 💫
×TXintEE7aezp6QxNNtbghCXvmXJdgofEyr
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
bc1qj7caz3xfh5qd4ud3v3nh7k4tfl5lg8jh9er73e
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
3TndfWAhPytTaBZjC2GbNWqh9iWx171SYACjbG2j5vx8
DHsrtwiL56Xk1xAj3fe8pVcfLhE8xgt3EQ
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
UQDFkubJxb8KmxFmy1arJxkewzmNEg6-G2pJFVzFihB65d7W
ltc1q3fentl6ur9cxm0vxyqkdmmzxkj92j00p9l8m7z
✍ Article Author
- Registration: 26 July 2025, 19:34
- Location: Georgia