


Edge AI: Why Artificial Intelligence Is Moving from the Cloud to Devices
 Tornike Moss
Tornike Moss

In the modern digital era, where data generation is reaching unprecedented scale, traditional cloud computing faces serious challenges. The first wave of artificial intelligence was powered by centralized servers and massive computational resources. Today, however, when every millisecond is critical—whether steering autonomous vehicles or analyzing critical medical data—the old paradigm is shifting. This is where AI inference at the edge enters the picture—a technological approach ensuring that AI models run not in distant data centers but directly at the source of data generation (on smartphones, industrial IoT sensors, and robots).
This is not merely a technical evolution; it is a fundamental strategic transformation. Edge AI fundamentally changes how real-time decisions are made, minimizes network latency, enhances data privacy, and ensures more efficient use of expensive cloud resources. In this article, we will thoroughly examine how Edge AI transforms local devices into independent, intelligent systems, the challenges it brings, and why it represents the backbone of future technological infrastructure.
Quick Summary
Key takeaways: The main ideas and conclusions of the article are summarized below.
- Edge AI refers to running artificial intelligence models directly on local devices such as smartphones, cameras, industrial sensors, or robots, rather than relying on distant cloud servers.
- Unlike traditional cloud-based architectures, edge inference processes data locally, drastically reducing network latency and enabling real-time decision making.
- This decentralized approach improves reliability because intelligent systems can continue operating even without a stable internet connection.
- Edge AI significantly enhances data privacy, as sensitive information can be processed on-device without transmitting raw data to centralized servers.
- By filtering and analyzing data locally, Edge AI also reduces network bandwidth usage and lowers the computational burden on expensive cloud infrastructure.
Table of Contents
What is AI Inference at the Edge?
The AI lifecycle is divided into two primary phases: training and inference. While the training process involves feeding massive volumes of data to a neural network to learn patterns, inference is the real-time execution process where the already "learned" model draws conclusions, makes predictions, or classifies based on new, unseen data. Traditionally, both phases were executed in centralized data centers. However, Edge AI inference fundamentally changes this architecture by shifting computational processes directly to the network's periphery—to the physical source of data generation (smartphones, cameras, robots, or IoT sensors).
Comparing Cloud and Edge Computing Paradigms
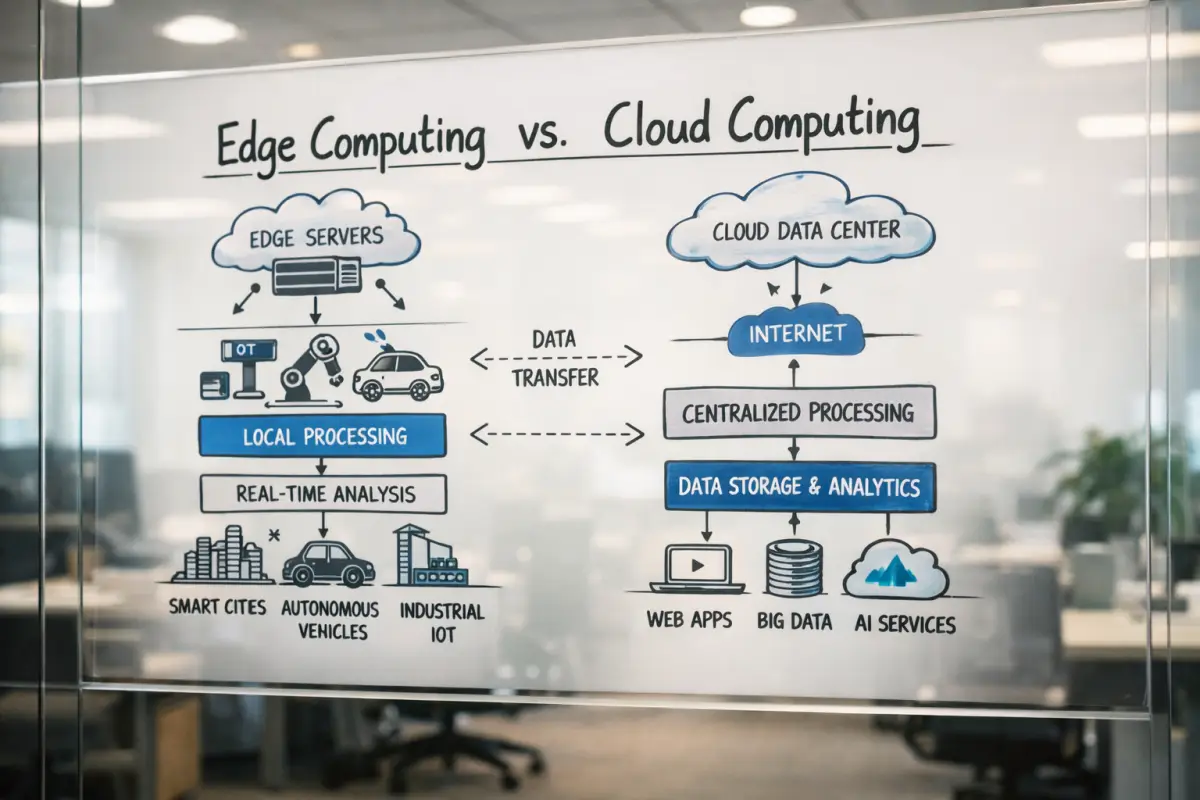
Over the past decade, total cloud dependency was the industry standard. Under this paradigm, a local device merely acts as a data collector: it gathers information, transmits it to a central server, the server processes the data using powerful processors, and returns the corresponding command or response. This architecture works perfectly for tasks where time is not a critical factor; however, in modern, high-intensity scenarios, it reveals serious, often insurmountable flaws.
The main technical limitation of cloud computing is latency. Latency is the time interval required for a data packet to travel from the device to the server and back (round-trip time). The laws of physics and the limits of network infrastructure mean that data transmission always requires a certain number of milliseconds. Imagine an autonomous driving system where a sensor detects an unexpected obstacle on the road. If the vehicle must send a video frame to the cloud, wait for the AI model to analyze it, and then receive a braking command, this 100–200 millisecond delay could lead to catastrophic consequences.
Beyond latency, total cloud dependency creates a bandwidth crisis. The continuous transmission of 4K video streams, audio files, or sensor telemetry generated by millions of devices can overload the network and is economically highly inefficient. Add to this the risk of unstable internet connectivity: if the network drops, a cloud-dependent "smart" device instantly loses its intelligence.
Edge computing fundamentally changes this paradigm through decentralization. By moving the decision-making center to the local level, the system becomes autonomous. The device no longer requires a constant internet connection to execute critical operations, making it significantly more reliable and faster.
Local Data Processing Architecture
For an edge device to operate independently, a specific technical architecture based on the integration of pre-trained models is required. As noted, training a model from scratch demands colossal computational power, so this process remains in the cloud or specialized data centers. However, once the model is trained and reaches the desired level of accuracy, its architecture and weights are frozen. The result is a pre-trained model representing a complete, functional algorithm.
Porting and running this model on local hardware requires the implementation of on-device processing mechanisms. On a technical level, this process unfolds as follows: the pre-trained model is loaded directly into the physical memory of a smartphone, robot, or sensor. When the device's camera or microphone captures new data, this data is not transmitted over the network. Instead, it is fed directly to the device's local processor.
Here, the inference engine—specialized software optimized for specific hardware—plays a critical role. It ingests raw data, passes it through the neural network residing in local memory, and generates an output in fractions of a second. This on-device processing architecture means that the entire data lifecycle—collection, analysis, and response—is executed within a single isolated environment.
Under this architecture, the device's relationship with the cloud changes. Instead of the server being the decision-maker, it becomes an orchestrator and an archive. The edge device sends the server not raw, heavy data, but only final, processed metadata (for instance, rather than the camera's entire video recording, it sends a text payload: "Object X detected at Time Y"). Concurrently, the cloud periodically and asynchronously delivers new, improved versions of the model to the local device. This hybrid but edge-focused architecture creates an intelligent ecosystem that combines local agility with global scalability.
Strategic Advantages of Edge AI
Transitioning to a local data processing architecture, as discussed above, is far more than a mere technical evolution. It represents a fundamental strategic shift that enables organizations to overcome the physical and economic barriers of traditional infrastructure. When intelligence moves directly to the point of data generation, entirely new capabilities are born—capabilities that are critically important for modern ecosystems focused on speed, security, and efficiency.
Zero Latency and Real-Time Decision Making
In the digital world, time is the most expensive currency. For systems where events unfold in fractions of a second, the round-trip time required to communicate with cloud servers is not a luxury, but a fatal risk. This is where one of Edge AI's most powerful advantages emerges—zero latency. The term "zero" here implies a practical minimum, where data processing occurs so rapidly that it is perceived as an instantaneous response by the user or mechanism.
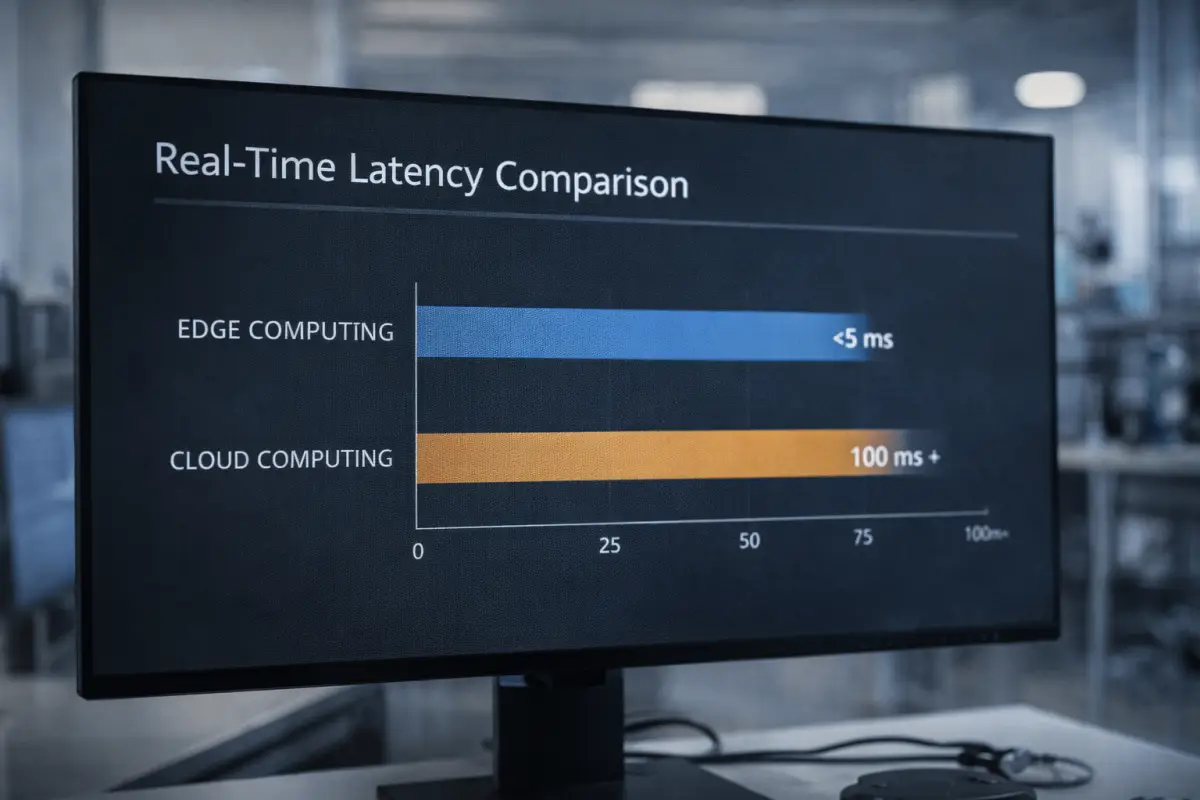
In time-critical systems, milliseconds decide everything. Take autonomous driving systems or industrial robotics. When a sensor on an unmanned vehicle traveling at 120 km/h suddenly detects a pedestrian, the vehicle does not have the time to send a video frame to a data center hundreds of kilometers away, wait for a neural network to analyze it, and then receive a braking command. This process could take 100–200 milliseconds, which translates to several meters of fatal delay in the physical world. Executing inference locally, directly on the vehicle's onboard computer, ensures decision-making in under 10 milliseconds. Similarly, in factories where robotic arms work alongside humans, Edge AI instantly halts the mechanism if a person enters a hazardous zone. This real-time decision-making capability makes Edge AI a guarantor of safety and autonomy.
Data Privacy and the New Security Standard
In an era of data leaks and massive cyberattacks, information security has become the number one priority for enterprises. The traditional cloud model is inherently vulnerable: data is constantly in transit across the network, creating the risk of man-in-the-middle attacks, while centralized servers storing petabytes of sensitive information represent prime targets for hackers—acting as a honeypot.
Edge AI tackles this problem at its root through the principle of data privacy by design. Because data processing and inference occur directly on the local device (in a smartphone, medical sensor, or security camera), raw, personal information never leaves the physical boundaries of the device. For example, a facial recognition system analyzes biometric data within the camera itself and sends the server not your photo, but only an encrypted, anonymous token verifying successful authorization.
This approach dramatically reduces the attack surface. Even if the network is compromised, an attacker cannot steal users' private conversations, health records, or video footage, simply because this information does not traverse the network. Furthermore, local processing helps organizations easily comply with strict international data protection regulations, such as GDPR or HIPAA, as the collection and centralized storage of sensitive data are minimized.
Network Bandwidth and Cloud Resource Optimization
Imagine a major metropolitan highway during rush hour. If all vehicles simultaneously attempt to pass through a single narrow checkpoint, a colossal traffic jam ensues, paralyzing movement entirely. The exact same principle applies to digital networks. In the era of billions of IoT devices, if every camera, sensor, and smartphone begins sending raw, unprocessed data (e.g., 4K video streams or continuous telemetry) to the cloud, network bandwidth will simply collapse, or maintaining it will incur astronomical costs.
Edge AI acts as an intelligent filter on this highway. The device locally analyzes the massive data stream and activates only when it detects something significant. Instead of a security camera sending 24 hours of empty street footage to a server, it analyzes the frames itself and transmits to the cloud only the 10-second clip (or just a textual metadata flag) when a suspicious object appears in the frame.
This architecture drives massive economic and infrastructural optimization. First, direct data transmission costs are drastically reduced. Second, and equally important, it achieves cloud offloading. Companies no longer have to spend millions of dollars on compute power and massive storage in Amazon AWS, Microsoft Azure, or Google Cloud for every trivial operation. Heavy, routine computational workloads are distributed across millions of devices at the periphery, while expensive cloud resources are reserved solely for high-level analytics, subsequent model improvements, and global orchestration.
Real-World Applications
Transitioning from theoretical advantages—such as zero latency, local data isolation, and bandwidth optimization—to practical engineering outcomes reveals that Edge AI is no longer just a laboratory concept. Today, it represents the critical infrastructural foundation upon which the digital industries of the future are being built. When intelligence shifts directly to the point of contact with the physical world, it transforms traditional devices into autonomous, reliable, and highly efficient systems. Let us examine three primary sectors where edge inference has already sparked an architectural revolution.
Autonomous Transport and Smart Cities
Autonomous driving systems represent one of the most complex and impressive engineering tests for Edge AI. A modern unmanned vehicle is equipped with dozens of sensors—high-resolution cameras, radars, and LiDAR systems—generating gigabytes of raw data per second. Sending this massive volume of information to the cloud and awaiting a response is, as noted in the previous chapter, physically and logically impossible.
Here, sensor fusion at the edge plays a decisive role. The vehicle's powerful onboard computer, equipped with specialized neural processing units (NPUs/GPUs), locally and synchronously processes streams from various sources. Computer vision algorithms analyze the 3D environment in fractions of a second: they recognize traffic signs, track the movement trajectories of pedestrians, and distinguish static objects from dynamic ones. This instantaneous sensor fusion ensures decision-making in milliseconds, which is critical for safety.
Concurrently, smart city infrastructure employs the exact same logic. Intelligent traffic lights and road cameras process video streams locally to assess traffic density and optimize light cycles. Instead of heavy video files, only structured metadata (e.g., "40 vehicles at the intersection") is sent to the central server, sharply reducing the load on municipal networks.
Industrial IoT and Predictive Maintenance
In heavy industry, the energy sector, and modern factories (Industry 4.0), unexpected machinery downtime costs companies millions of dollars annually. The traditional approach—repairing a mechanism after it breaks or conducting scheduled, calendar-based inspections—is highly inefficient. Edge AI introduces an entirely new standard: predictive maintenance.

Industrial equipment (turbines, generators, conveyors) is equipped with vibrational, acoustic, and thermal sensors that perform thousands of measurements per second. An edge device, mounted directly on the machinery, continuously feeds these signals into a local neural network (anomaly detection models). The model is trained on the specific patterns of normal operation and can detect micro-anomalies imperceptible to the human ear or traditional software (for instance, slight vibration in a motor bearing indicating wear and tear).
Because the analysis occurs locally, the factory's internal network is not burdened with terabytes of telemetry data. The system only dispatches a critical alert when it determines that the mechanism will likely fail in, say, three weeks. This engineering approach radically increases hardware lifespan, eliminates catastrophic shutdowns, and saves companies gigantic sums in infrastructure renewal costs.
Healthcare Technological Infrastructure and Data Security
The implementation of Edge AI in the healthcare sector must be examined strictly from an engineering and data architecture perspective. Modern hospitals and portable medical devices (wearables, ICU monitors) continuously collect sensitive patient biometric data (ECG, blood oxygen levels, pulse). Streaming this raw data continuously to the cloud creates two massive problems: cybersecurity risks and the danger of connectivity loss.
Local inference guarantees the highest standard of data protection and simplifies compliance with stringent regulations like HIPAA. Under an edge architecture, the analysis of biometric signals takes place directly on the device's processor. Raw, personally identifiable medical data never leaves the device. Instead, only encrypted, anonymous metadata or critical alerts (e.g., a request to summon a nurse) are sent to the cloud. This privacy by design approach makes it virtually impossible for hackers to intercept massive patient databases at the device level.
Beyond confidentiality, this engineering architecture is vital in zero-connectivity environments. For instance, in emergency helicopters, remote regions, or natural disaster zones where internet connectivity is unstable or nonexistent, a cloud-dependent monitor would simply shut down. An edge device, however, maintains full autonomy: the local model continues to analyze vital signs and can instantly trigger a local alarm system upon detecting a critical deviation, completely independent of access to an external network. This makes the medical IoT infrastructure maximally resilient against any engineering or communication disruptions.
Technical Challenges and Solutions
Although the concept of edge inference appears strategically flawless, realizing it in the physical world represents one of the most formidable tests of modern engineering thought. Fitting a neural network with billions of parameters into a microscopic chip that lacks both a powerful cooling system and unlimited electricity pushes the boundaries of physics and computer science. This is precisely why the evolution of Edge AI is directly intertwined with hardware innovations and aggressive, multi-layered algorithm optimization.

Hardware Constraints and the Role of NPUs
Modern artificial intelligence models—whether large language models or complex computer vision architectures—are exceptionally "heavy." They demand gigabytes of RAM and colossal memory bandwidth. Edge devices (IoT sensors, smartphones, industrial cameras), however, are strictly constrained by physical dimensions and memory capacity. Here we encounter the memory wall phenomenon: in traditional Von Neumann architecture, moving data from memory to the processor consumes significantly more time and energy than performing the mathematical computation itself.
Traditional central processing units (CPUs) are designed for serial, general-purpose operations and are not tailored for the massive, parallel matrix computations characteristic of neural networks. Graphics processing units (GPUs) excel at this, but they are extremely power-hungry and occupy large physical footprints.
To resolve this architectural crisis, the industry engineered neural processing units (NPUs), also known as AI accelerators. An NPU is a specialized microchip (ASIC) whose silicon architecture is physically optimized for tensor mathematics. Instead of a chip performing every type of task, it focuses on one thing: executing the multiply-accumulate (MAC) operations of a neural network at maximum speed. The integration of NPUs into local devices (within System-on-Chip architectures) has radically changed the rules of the game. They can perform trillions of operations per second (TOPS) while keeping data within local, high-speed cache memory (SRAM), effectively dismantling the memory bottleneck.
Energy Efficiency and Thermal Management
As computational power increases, the unforgiving law of thermodynamics comes to the forefront: intensive mathematical operations generate heat and consume energy. Most edge devices, such as portable medical sensors, smartwatches, or field drones, operate on limited-capacity batteries. They lack the luxury of active cooling (fans or liquid cooling). If an AI model fully maxes out the processor, the device will overheat in minutes, triggering thermal throttling—an automatic dramatic slowdown of the system to prevent the processor from burning out. Concurrently, battery life is instantly depleted.
In response to this challenge, engineering focus has shifted to a new metric: TOPS/Watt (trillions of operations per second per watt of energy). The goal is not merely brute performance, but absolute energy efficiency. To achieve this, hardware-software co-design is utilized. The system spends the majority of its time in an ultra-low-power "sleep" mode. Microcontrollers employ a cascading architecture: an extremely small model operating on milliwatts continuously listens to the environment (e.g., waiting for a voice command or motion in a frame) and only wakes the main, powerful NPU to conduct full inference after detecting a specific trigger. This thermal management is vital for the long-term autonomy of edge devices.
Model Optimization Techniques

Hardware innovations alone cannot solve the size problem. To fit giant neural networks into the constrained space of edge devices, it is essential to programmatically "compress" and transform the models themselves. This is achieved through three fundamental techniques of algorithmic optimization:
1. Quantization:
By default, during the training process, neural network parameters (weights and activations) are stored in a 32-bit floating-point (FP32) format. This ensures maximum mathematical precision but demands immense memory. Quantization is a mathematical process that reduces the precision of these numbers during the inference phase—for example, from FP32 down to 8-bit integers (INT8) or even a 4-bit format (INT4). Imagine compressing a high-resolution RAW photo into an optimized JPEG format: the file size shrinks by a factor of 4 or 8, multiplying integers becomes vastly simpler and faster for the processor, while the model's predictive accuracy drops only marginally, often by just 1-2%. This trade-off between accuracy and speed is the gold standard of Edge AI.
2. Pruning:
Neural networks, much like biological brains, are often over-parameterized. After training is complete, a large portion of the synaptic connections in the network is functionally useless, or their weights are very close to zero—they do not play a critical role in final decision-making. The pruning algorithm identifies and removes these "dead" neurons and connections. The result is a sparse matrix. Thanks to structured pruning, the model's architecture becomes significantly lighter, occupies less space, and allows the NPU to simply skip useless multiply-by-zero operations, saving both time and energy.
3. Knowledge Distillation:
This is one of the most elegant architectural approaches, based on a teacher-student paradigm. The process begins with a massive, highly accurate model (the teacher), which can only be run on a powerful cloud server. Engineers then create a much smaller, compact model (the student) with limited parameters. However, instead of training the student model on raw data, it is trained on the decisions generated by the teacher model (soft labels). The student model learns not just the dry facts, but the "essence" of the teacher's behavior, its generalization logic, and hidden patterns. It is akin to a professor distilling years of experience into a single, compact textbook. The result is a miniature model that can comfortably run on an edge device while retaining the vast majority of its giant teacher's accuracy and intelligence.
The Future of Intelligent Ecosystems
The evolution of artificial intelligence clearly demonstrates that the era of cloud-only architectures is drawing to a close. It is being replaced by a new, long-term industry standard—the intelligent edge. However, this strategic transformation does not imply the rejection of traditional cloud technologies. On the contrary, we are transitioning into an era of hybrid intelligence. In this new, balanced ecosystem, model training, global data archiving, and system orchestration remain on centralized servers, while instantaneous, critical decision-making shifts directly to the periphery, at the point of contact with the physical world. Edge AI is precisely the invisible yet most powerful backbone of this hybrid future.
Overcoming the hardware constraints discussed in previous chapters and the masterful optimization of algorithms have laid a solid foundation for the digital innovations of the next decade. When billions of devices—whether autonomous transport, medical sensors, or industrial robots—possess the ability to think independently, with zero latency and without a constant internet connection, we will achieve an entirely new, autonomous technological landscape. Systems will become not only unprecedentedly fast and economical but, most importantly, secure and privacy-preserving by design.
Ultimately, AI inference at the edge is no longer merely a technological trend. It is a fundamental step toward a world where innovation and security coexist in harmony. Thanks to this paradigm, the technology of the future will serve society invisibly, reliably, and instantaneously, exactly where and when it is needed most.
If you want to understand why traditional cloud infrastructure alone is no longer sufficient for modern distributed systems, read our analytical article — Edge Computing vs Cloud: Why Cloud Alone Is No Longer Enough.
Go backComments (0)
From This Author
Select Crypto to Support the Author 💫
×TXintEE7aezp6QxNNtbghCXvmXJdgofEyr
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
bc1qj7caz3xfh5qd4ud3v3nh7k4tfl5lg8jh9er73e
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
3TndfWAhPytTaBZjC2GbNWqh9iWx171SYACjbG2j5vx8
DHsrtwiL56Xk1xAj3fe8pVcfLhE8xgt3EQ
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
UQDFkubJxb8KmxFmy1arJxkewzmNEg6-G2pJFVzFihB65d7W
ltc1q3fentl6ur9cxm0vxyqkdmmzxkj92j00p9l8m7z
✍ Article Author
- Registration: 26 July 2025, 19:34
- Location: Georgia