


Algorithmic Bias: Data Asymmetry, Optimization, and the Illusion of Neutrality
 Tornike Moss
Tornike Moss

In the contemporary technological era, artificial intelligence systems are not merely computational instruments; they are complex socio-technical constructs that actively shape fundamental aspects of human life. At the epicenter of this transformative process lies the phenomenon of algorithmic bias, which is frequently misconstrued as a simple software malfunction. In reality, algorithmic bias is not a mere technical defect; it emerges organically from asymmetries in data distributions, from the optimization objectives embedded in machine learning models, and from the broader socio-technical contexts within which these models operate. The illusion of neutrality is deeply embedded in public discourse: the belief that mathematical formulas and statistical models are insulated from human subjectivity. Yet this perspective overlooks a crucial fact: an algorithm is an inductive mechanism that extrapolates from historical patterns in order to generate predictions about the future.
Accordingly, any algorithmic system constitutes a mathematical reflection of the historical data on which it has been trained. A serious discussion of AI ethics requires an examination of the foundational mechanisms that govern model behavior. Algorithmic decision-making relies on probabilistic logic and statistical inference; outputs emerge from complex interactions among input variables. In this process, bias is not integrated through deliberate authorial intent, but through the architectural and statistical properties of the system itself. The methodologies of data collection and the metrics used to evaluate model performance jointly create an environment in which systematic deviations become inevitable.
The epistemological nature of artificial intelligence diverges fundamentally from that of classical programming. In traditional systems, rules are explicitly defined by human designers, whereas in the machine learning paradigm, models infer regularities from empirical observations. It is precisely at this inductive leap that the illusion of objectivity collapses. An algorithm cannot distinguish correlation from causation; any statistically robust association is treated as a valid predictive signal. When we describe algorithmic bias as a socio-technical phenomenon, we mean that social structures and historical inequalities become encoded in data and are subsequently legitimized through algorithmic authority. In the first phase of this multi-part analytical series, our focus is on the technical and methodological foundations that generate bias, and on the detailed mechanisms through which data asymmetry and optimization processes crystallize into systematic distortions.
Table of Contents
- The Technical Foundations of Algorithmic Bias: Data Distribution and the Optimization Function
- Sampling Bias, Label Distortion, and Feedback Loops
- Mathematical Fairness Metrics and Their Limitations
- Bias Mitigation Strategies: Pre-, In-, and Post-Intervention
- Why an Algorithm Can Never Be Fully Neutral
- Analytical Synthesis
The Technical Foundations of Algorithmic Bias: Data Distribution and the Optimization Function
The fundamental objective of a machine learning model is to learn a function that maps input variables to desired outputs with maximal predictive accuracy. To properly conceptualize bias in this context, it is necessary to distinguish the statistical notion of bias from its broader sociological meaning. In statistics, bias refers to a systematic discrepancy between predicted values and true values. Within machine learning, high bias indicates a model’s inability to capture complex relationships. However, when we discuss algorithmic bias in the domain of AI ethics, we refer to the systematic and disproportionate effects that model-generated outcomes have on different social groups.
This systematic deviation is directly linked to data distribution. Any model is trained on a specific dataset that represents a statistical distribution within a multidimensional space. If this distribution is asymmetric—meaning that certain classes are overrepresented while others are underrepresented—the training process internalizes that asymmetry within the model’s parameters. Training is, in essence, a mechanism of empirical risk minimization. The model architecture relies on an objective function that defines the optimization target and on a loss function that quantifies error magnitude. Algorithms such as gradient descent iteratively update model weights in order to minimize total loss across the entire training set.
It is precisely here that a critical dissonance emerges between optimization and fairness. Minimizing a loss function entails reducing global average error. When the training data are dominated by a majority class, it becomes mathematically rational for the model to prioritize mastering patterns associated with that class, since doing so ensures the most rapid reduction in aggregate loss. Errors affecting minority classes exert only marginal influence on the overall gradient; consequently, the algorithm exhibits a structural tendency to disregard rare cases.

Optimization does not imply fairness; mathematical optimization algorithms lack any contextual understanding of equality. For the model, each data point is merely a vector, and the objective is the minimization of a scalar value.
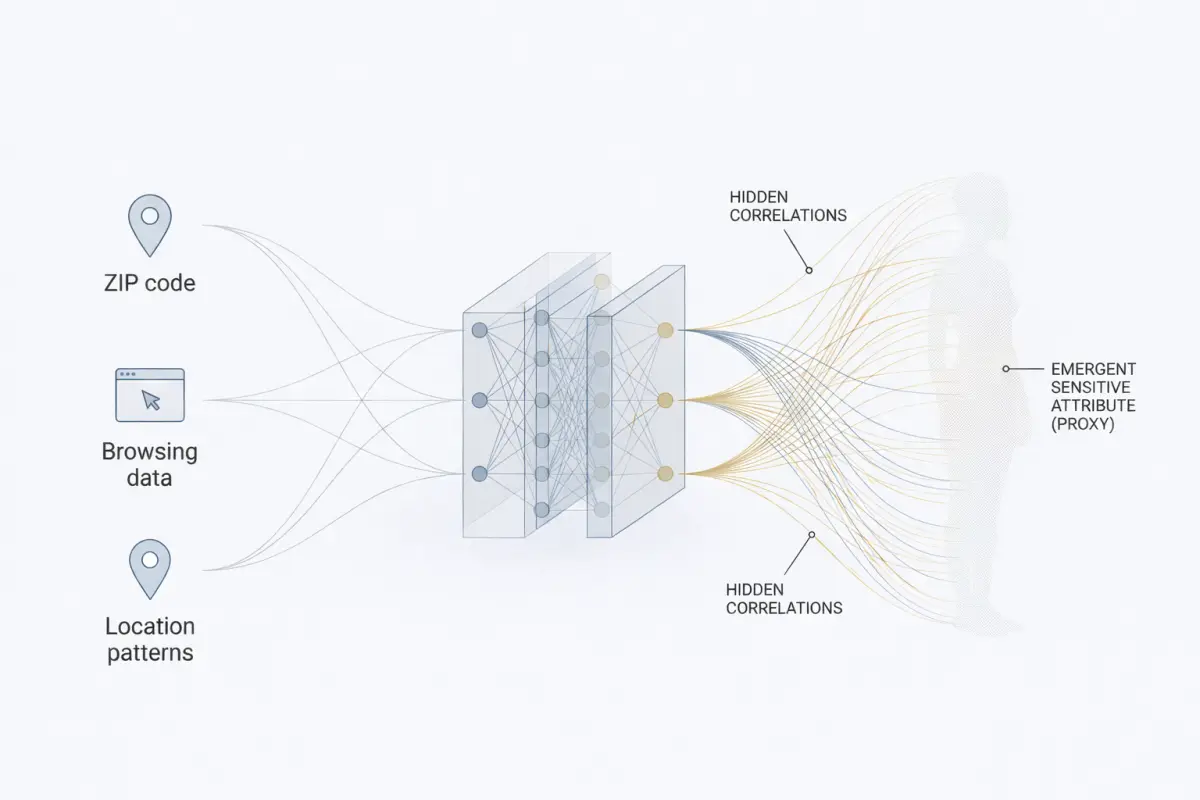
This structural limitation of optimization becomes particularly critical in high-dimensional data spaces, where correlations are often latent and non-transparent. The algorithm identifies the shortest path toward error minimization, even if that path relies indirectly on socially sensitive attributes such as race, gender, or socioeconomic status. In technical terms, this phenomenon is referred to as proxy discrimination, whereby the model does not explicitly use a prohibited attribute but instead relies on other variables that are statistically correlated with it.
Consequently, a model exhibiting high global accuracy may still be sharply biased against specific subpopulations. For instance, if a model is trained on data in which ninety percent of samples belong to a single demographic group, it may achieve impressive overall accuracy simply by effectively ignoring the remaining ten percent. From a technical perspective, this constitutes a successful optimization process, since the loss function has been minimized. From a socio-technical perspective, however, it represents a structural dysfunction. The model’s weights, which encode learned information, become mathematical crystallizations of data imbalance. An optimization paradigm oriented toward satisfying majority patterns structurally precludes equal representation without explicit corrective interventions.
Consider, for example, cross-entropy loss or mean squared error. These functions evaluate model performance in aggregate. When the data space exhibits pronounced asymmetry, the parameter update vector is primarily determined by the characteristics of the dominant group. Rare instances are treated as statistical noise or anomalous observations. The model’s capacity for generalization, intended to prevent overfitting, paradoxically results in the erasure of minority-specific features. The outcome is a system that is technically optimized but contextually problematic, because it establishes a normative standard that is relevant only to the majority represented in the data.
Sampling Bias, Label Distortion, and Feedback Loops
Beyond technical optimization, the roots of algorithmic bias lie directly in the processes of data generation and collection. One of the most critical issues in this domain is sampling bias, which arises when the training dataset does not constitute a randomized and representative sample of the real-world population to which the model will be deployed. In statistical terms, if the sampling process is neither independent nor identically distributed, the model’s inferences lose validity. Representational imbalance implies that the lived experiences of certain groups are systematically excluded from the dataset. When a model is trained within such a deficient space, what is absent from the data is effectively absent from reality for the system. This produces an epistemological blindness, rendering the system incapable of recognizing input signals from groups marginalized during the training phase.
Closely related to sampling bias is label bias, which reflects a structural feature of supervised learning paradigms. In supervised learning, the algorithm requires ground truth—that is, pre-labeled data. Yet these labels rarely constitute objective truth; they are products of human judgment or historically situated processes. Label distortion occurs when we attempt to algorithmically predict an abstract construct but instead rely on a tangible, yet biased, proxy variable. For example, if the objective is to predict the probability of criminal behavior, the dataset may in practice be labeled not with actual instances of crime, but with recorded arrests. Arrest is not an objective measure of criminality; it reflects patterns of police patrol allocation and historically entrenched practices that may themselves contain structural asymmetries. When a model learns from such distorted labels, it effectively replicates and automates structural bias.

A further illustrative case of label bias can be found in hiring algorithms. If an organization has historically hired and promoted primarily individuals from a specific demographic group, the ground truth defining a “successful employee” will be saturated with the attributes of that group. An algorithm trained on historical resumes will systematically assign lower evaluations to candidates with divergent profiles—not because they are less qualified, but because their features deviate from historically labeled patterns of success.
These structural defects are further amplified through feedback loops. Machine learning systems do not operate in isolation; they are embedded within dynamic systems in which model outputs actively reshape the environments in which they function. A feedback loop is a self-reinforcing mechanism in which an algorithm’s outputs influence the generation of future data, which in turn become part of the same algorithm’s training corpus. This creates a closed cycle in which initial bias intensifies over time.
Consider predictive policing systems or recommendation algorithms. If a model concludes that a specific geographic area poses elevated risk, additional resources are deployed there. Increased surveillance naturally leads to more recorded incidents, which are subsequently fed back into the system as new data. The model interprets these data as confirmation of its prior prediction. A similar dynamic operates in informational ecosystems: a recommendation system proposes content based on a user’s past behavior; the user consumes the recommended content; this behavior further reinforces the model’s parameters. Feedback loops erode the boundary between prediction and the construction of reality. The model becomes an active instrument in shaping the environment, transforming biased forecasts into self-fulfilling prophecies. Within this dynamic process, the algorithmic system loses the capacity to objectively correct its own errors, because each new data point is not an independent empirical observation, but an artifact generated by its prior decisions. The cyclical nature of data ensures that initial asymmetries solidify into persistent statistical realities.
Mathematical Fairness Metrics and Their Limitations
Attempts to evaluate the fairness of algorithmic systems have led to the development of a diverse array of mathematical fairness metrics designed to quantify bias. Yet this effort has exposed a fundamental epistemological problem: fairness is not a universal, monolithic concept amenable to unambiguous mathematical formalization. Within both industry and academia, several core metrics are widely employed, each grounded in a distinct philosophical conception of justice. Demographic parity requires that the rate of positive outcomes be identical across all social or demographic groups, irrespective of differences in the baseline distribution of the target variable across those groups. This approach is oriented toward compensating for historical inequalities, but it frequently encounters tension with predictive accuracy, since it disregards genuine statistical disparities between groups.
By contrast, the metric of equalized odds focuses not on the uniform distribution of outcomes, but on the symmetry of error rates. Under this standard, an algorithm is considered fair when true positive rates and false positive rates are identical across all protected groups. This implies that the model must serve different populations with equal predictive performance and must not commit disproportionately higher error rates against any particular minority group. In addition, there exist the concepts of predictive parity and calibration, which require that the probabilities assigned by the model objectively reflect real-world likelihoods across all groups. If an algorithm assigns a seventy percent probability to an event, that event should occur in seventy percent of cases, regardless of the demographic category of the subject.
Despite the internal logical validity of each metric, machine learning theory imposes strict mathematical constraints that render their simultaneous satisfaction impossible. The impossibility theorems articulated by Kleinberg, Mullainathan, and Raghavan demonstrate that if different groups exhibit distinct base rates for the target variable, it is mathematically infeasible to achieve both equalized odds and predictive calibration at the same time. The only exception arises in the hypothetical scenario of perfect predictive accuracy. These impossibility results confirm that selecting among fairness metrics is not a matter of technical optimization; it is a fundamental normative trade-off requiring a decision about which types of errors are more acceptable within a given social context.
Bias Mitigation Strategies: Pre-, In-, and Post-Intervention
Once the existence of algorithmic bias and the difficulty of measuring it become evident, engineering efforts turn toward mitigating these deviations. Bias reduction, or debiasing, strategies are traditionally categorized into three primary approaches, depending on the stage of model development at which intervention occurs. Pre-processing focuses on modifying the training data before the algorithm begins interacting with them. Techniques at this stage include reweighting, whereby records representing marginalized groups are assigned greater statistical weight in order to compensate for their underrepresentation. Resampling methods are also widely used to artificially balance class distributions within the dataset. The objective is to construct a training space free from historical asymmetries; however, this often entails a partial loss of the natural structure of the original data. The modification of historical data also generates ethical dilemmas, raising the question of whether it is legitimate to alter empirical records of the past in order to model a more desirable future.
A second, more complex strategy is in-processing, which intervenes directly within the training algorithm itself. In this approach, specific fairness constraints are incorporated into the optimization objective, compelling the model to satisfy predefined fairness metrics alongside loss minimization. Through the use of Lagrange multipliers or analogous optimization techniques, the algorithm seeks an equilibrium point between the reduction of predictive error and the attainment of fairness gains. Particular attention has been devoted to adversarial debiasing techniques inspired by generative adversarial architectures. In such configurations, a primary model attempts to perform its predictive task while a parallel adversarial model seeks to infer sensitive attributes from the primary model’s internal representations. The objective of the primary model is to learn representations that retain predictive power yet are uninformative with respect to protected characteristics. Although this approach can be effective, it substantially increases computational complexity and often introduces instability during training.
The third approach, post-processing, involves adjusting the outputs of an already trained model. In this case, the internal parameters of the algorithm remain unchanged, but decision thresholds are modified for different groups. For example, if a model systematically underestimates the likelihood of positive outcomes for a particular group, engineers may lower the classification threshold for that group in order to achieve equalized odds. This method is particularly problematic from a legal standpoint, since it explicitly employs protected characteristics to impose differential treatment, a practice that directly conflicts with anti-discrimination legislation in many jurisdictions. Although these mitigation strategies are technically sophisticated, they are subject to fundamental limitations. Any form of debiasing necessarily entails a trade-off between overall model accuracy and fairness. Moreover, such methods often treat sensitive attributes as isolated variables and fail to address intersectional inequalities, where bias emerges from the complex interaction of multiple identities.
Why an Algorithm Can Never Be Fully Neutral
The existence of technical mitigation strategies frequently fosters the mistaken expectation that, with sufficient engineering effort, it is possible to construct a fully neutral and objective algorithm. However, the ontological nature of machine learning precludes complete neutrality. First and foremost, the optimization process itself is a value-laden act. When a developer selects an objective function, a normative decision is made regarding what the system should prioritize. Whether a system is optimized for maximum profit, user engagement, or risk minimization directly shapes model behavior. An algorithm thus constitutes a mathematical extension of the institutional priorities and economic objectives of its creators.
Furthermore, the phenomenon of latent bias demonstrates that removing sensitive variables from a model is insufficient to achieve neutrality. In high-dimensional data spaces, nearly any ostensibly innocuous feature can function as a proxy for a prohibited category. Postal codes, musical preferences, or browsing histories encode information about an individual’s socioeconomic status, ethnic background, or gender. Machine learning models are fundamentally correlational engines lacking causal reasoning capacities. Consequently, they absorb and reproduce the structural traces of social inequality embedded within the data matrix. Deep neural networks, with their ability to detect latent correlations, will inevitably uncover and exploit these hidden structures if doing so contributes to loss minimization. Bias thus becomes not a superficial attribute, but a deeply woven feature of the system’s internal representations.
The illusion of neutrality is further destabilized by dependence on deployment context. An algorithm that exhibits a high degree of fairness within a specific social or geographic environment may become discriminatory when transferred to another context. Historical data patterns, behavioral norms, and institutional structures vary across time and space. When an algorithm is integrated into a new socio-technical ecosystem, its predictions may lose calibration relative to the new reality. Algorithmic neutrality is not a static property; it is a dynamic condition that evolves through interaction with its environment. From a socio-technical perspective, model and society are co-constructed, precluding the possibility of the algorithm functioning as an independent observer.
Analytical Synthesis
A comprehensive analysis of algorithmic bias demonstrates that inequality within artificial intelligence systems is not a mere software defect amenable to standard debugging procedures. Investigations into data distribution asymmetries, the mathematical blindness of optimization functions, and feedback loops—alongside impossibility theorems concerning fairness metrics—confirm that bias is an architectural and structural property of the system. The trade-offs inherent in mitigation strategies indicate that purely technological interventions will remain inherently limited in their effectiveness. Algorithms extrapolate from historical data and operate as amplifiers of preexisting power structures and statistical inequalities within society. The collapse of the illusion of neutrality necessitates a paradigmatic shift in AI development, one in which model evaluation extends beyond accuracy metrics to encompass continuous, context-sensitive analysis of socio-technical impact. Only through recognition of this multilayered complexity can systems be designed that minimize structural harm and enable more transparent, ethically informed algorithmic governance.
Go backComments (0)
From This Author
Select Crypto to Support the Author 💫
×TXintEE7aezp6QxNNtbghCXvmXJdgofEyr
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
bc1qj7caz3xfh5qd4ud3v3nh7k4tfl5lg8jh9er73e
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
3TndfWAhPytTaBZjC2GbNWqh9iWx171SYACjbG2j5vx8
DHsrtwiL56Xk1xAj3fe8pVcfLhE8xgt3EQ
0x9c6299454A6B617A0Db228024279F2a3EEf956dD
UQDFkubJxb8KmxFmy1arJxkewzmNEg6-G2pJFVzFihB65d7W
ltc1q3fentl6ur9cxm0vxyqkdmmzxkj92j00p9l8m7z
✍ Article Author
- Registration: 26 July 2025, 19:34
- Location: Georgia